


 我要发帖
我要发帖


一、Transformer
Transformer 是大模型的底层模型。在深度学习的早期阶段,循环神经网络(RNN)是处理序列数据的常用方法。尽管RNN及其变体在某些任务上表现良好,但它们在处理长序列时容易遇到梯度消失和模型退化问题。为了解决这些问题,Transformer模型被提出。
而后2020年 OpenAI首次提出“规模定律”,指出模型的性能随着参数量、数据量、训练时长的指数级增加而呈现出线性提升,并且该提升对架构和优化超参数的依赖性非常弱[7]。从此研究人员逐步转移研究重心至大语言模型基座,并开展了大量相关研究。基于Transformer的GPT、Bert等大模型在各种自然语言处理任务上取得了突破性的成果,包括文本生成、机器翻译、问答等,并展现了在零样本和少样本情况下的泛化性。
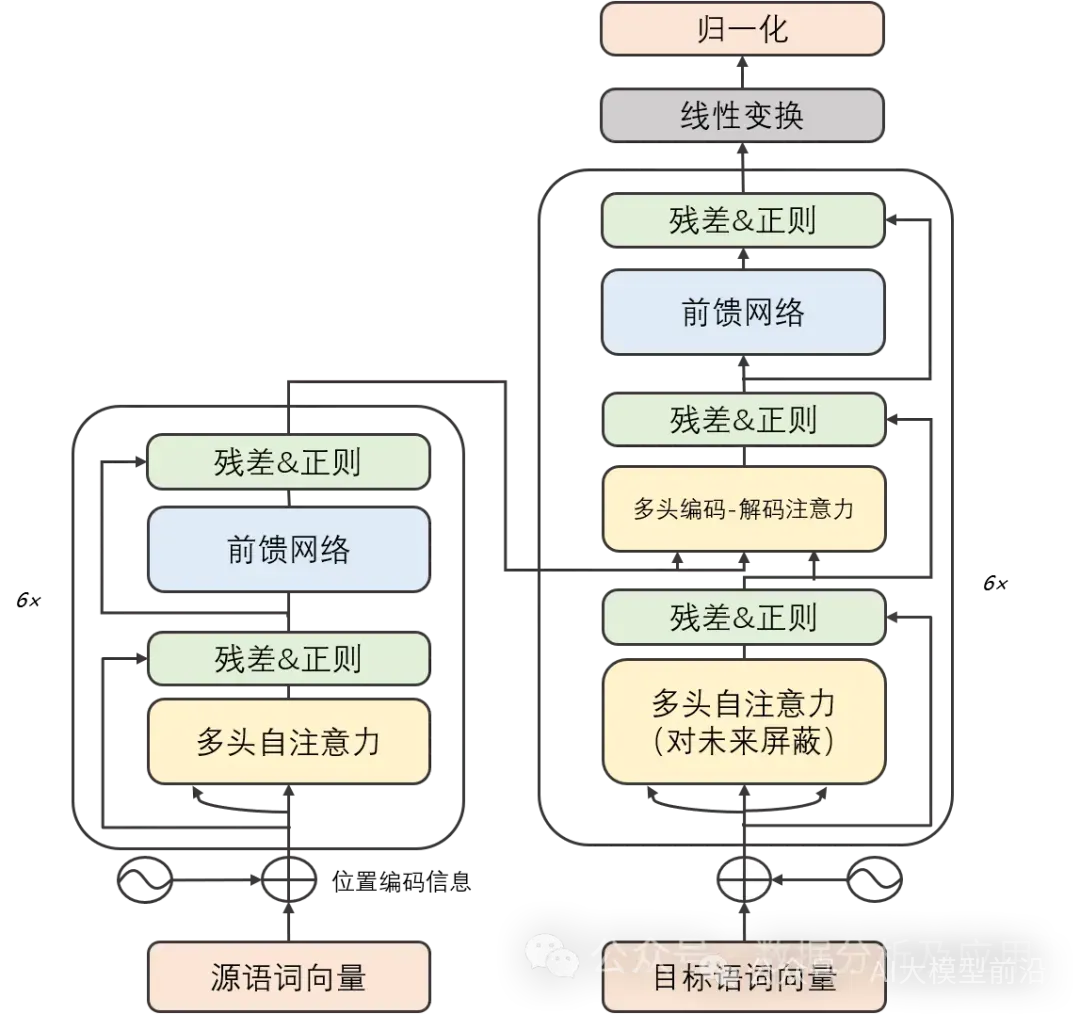
模型原理:
Transformer模型精巧地结合了编码器和解码器两大部分,每一部分均由若干相同构造的“层”堆叠而成。这些层巧妙地将自注意力子层与线性前馈神经网络子层结合在一起。自注意力子层巧妙地运用点积注意力机制,为每个位置的输入序列编织独特的表示,而线性前馈神经网络子层则汲取自注意力层的智慧,产出富含信息的输出表示。值得一提的是,编码器和解码器各自装备了一个位置编码层,专门捕捉输入序列中的位置脉络。
模型训练:
Transformer模型的修炼之道依赖于反向传播算法和优化算法,如随机梯度下降。在修炼过程中,它细致地计算损失函数对权重的梯度,并运用优化算法微调这些权重,以追求损失函数的最小化。为了加速修炼进度和提高模型的通用能力,修炼者们还常常采纳正则化技术、集成学习等策略。
优点:
- 梯度消失与模型退化之困得以解决:Transformer模型凭借其独特的自注意力机制,能够游刃有余地捕捉序列中的长期依赖关系,从而摆脱了梯度消失和模型退化的桎梏。
- 并行计算能力卓越:Transformer模型的计算架构具备天然的并行性,使得在GPU上能够风驰电掣地进行训练和推断。
- 多任务表现出色:凭借强大的特征学习和表示能力,Transformer模型在机器翻译、文本分类、语音识别等多项任务中展现了卓越的性能。
缺点:
- 计算资源需求庞大:由于Transformer模型的计算可并行性,训练和推断过程需要庞大的计算资源支持。
- 对初始化权重敏感:Transformer模型对初始化权重的选择极为挑剔,不当的初始化可能导致训练过程不稳定或出现过拟合问题。
- 长期依赖关系处理受限:尽管Transformer模型已有效解决梯度消失和模型退化问题,但在处理超长序列时仍面临挑战。
应用场景:
Transformer模型在自然语言处理领域的应用可谓广泛,涵盖机器翻译、文本分类、文本生成等诸多方面。此外,Transformer模型还在图像识别、语音识别等领域大放异彩。
二、预训练技术
严格意义上讲,GPT 可能不算是一个模型,更像是一种预训练范式,它本身模型架构是基于Transformer,再通过海量的大数据下进行预训练 ,使模型能够学习到数据的通用特征。这种技术广泛应用于计算机视觉、自然语言处理等领域,并为后续的特定任务提供了强大的基础。
核心原理:
大模型预训练技术的核心原理在于通过大规模数据的预训练来提取丰富的语言知识和语义信息。在预训练阶段,模型利用自注意力机制捕捉文本中的上下文信息,并通过学习大量的文本数据,逐渐理解语言的规律和结构。这种学习方式是自监督的,模型能够自我优化和改进,从而提高其对文本的理解能力。
在微调阶段,模型会根据具体任务的需求进行有针对性的调整。通过有监督学习的方式,模型在特定数据集上进行训练,以优化其在该任务上的性能。这种微调过程使得模型能够更好地适应不同任务的需求,并提高其在实际应用中的效果。
训练过程:
大模型的预训练技术的训练过程主要分为以下几个步骤:
- 数据收集与预处理:首先,收集大量的无标签数据,这些数据可以来自互联网上的各种文本资源,如网页、新闻、博客、社交媒体等。随后,对这些数据进行预处理,包括分词、去除停用词、标准化等操作,以便于模型更好地理解和处理。
- 模型选择:根据具体任务和数据特点,选择合适的预训练模型。这些模型可以是基于Transformer的,如BERT、GPT等,也可以是基于RNN或CNN的模型。
- 预训练:使用无标签数据对模型进行预训练。在这一阶段,模型会学习语言的结构和语义信息,通过自监督学习或无监督学习的方式,从海量文本数据中提取出有用的特征表示。
- 微调:针对具体的下游任务,使用有标签的数据对预训练模型进行微调。通过调整模型的部分参数,使其能够更好地适应特定任务的文本数据,从而提高在任务上的性能。
预训练技术的作用:
- 提升性能:通过在大规模数据集上进行预训练,模型能够学习到更多的语言知识和语义信息,从而提高其在各种任务上的性能。这种性能提升不仅体现在准确率上,还体现在模型的泛化能力和鲁棒性上。
- 加速训练:预训练模型已经过大量的数据训练,因此可以提供相对准确的初始权重。这可以避免在训练新模型时出现梯度消失或爆炸的问题,从而加快模型的收敛速度。此外,采用预训练模型来训练新的模型还可以节省大量的时间和计算资源。
- 提高泛化能力:由于预训练模型已经过多种数据集的训练,因此具有更强的泛化能力。这意味着模型能够更好地适应不同的任务和领域,减少过拟合的风险。
三、RLHF
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)RLHF是一种结合了强化学习和人类反馈的调优方法,旨在提高大模型在特定任务上的性能和可靠性。
RLHF的原理
RLHF的原理在于将强化学习与人类反馈相结合,通过人类的判断作为奖励信号来引导模型的行为。传统的强化学习依赖于环境提供的奖励信号来进行决策,而RLHF则利用人类对于模型输出的反馈作为奖励信号,使模型能够学习到更符合人类价值观的行为。
在RLHF中,人类反馈的作用至关重要。通过人类对模型输出的评价、标注或排序等方式,可以为模型提供关于其行为的直接反馈。这种反馈可以告诉模型哪些行为是受到人类认可的,哪些行为是需要改进的,从而帮助模型优化其决策过程。
RLHF的训练过程
RLHF的训练过程通常包括以下几个关键步骤:
- 预训练模型的选择与加载:首先,选择一个适合的预训练模型作为基础。这个预训练模型应该已经具备一定的通用能力,以便在后续的训练过程中进行微调。
- 监督微调(Supervised Fine-tuning,SFT):在这一阶段,模型通过模仿人类标注的对话示例来学习通用的、类似人类的对话。这有助于模型理解人类的对话模式和习惯,为后续的人类反馈学习打下基础。
- 奖励模型(Reward Model,RM)训练:为了利用人类反馈,需要训练一个奖励模型。这个模型会根据人类对于模型输出的标注或排序来学习如何评估模型的行为。具体来说,对于模型对同一个prompt的多个回复,利用人类标注来进行排序以获取人类偏好。然后,单独使用另一个语言模型作为奖励模型,在这个奖励模型上使用标注的数据进行训练。
- 近端策略优化(Proximal Policy Optimization,PPO):以训练得到的奖励模型作为奖励函数,继续对模型进行训练优化。通过不断迭代,模型会逐渐学会如何根据人类的反馈来改进其行为,使其输出更加符合人类的期望和标准。
RLHF的作用
RLHF在大模型技术中发挥着重要作用,具体体现在以下几个方面:
- 提高模型性能:通过结合强化学习和人类反馈,RLHF可以帮助模型更好地理解和适应特定任务的需求。通过人类的直接反馈,模型可以更加准确地把握任务的核心要点,从而提高其在任务上的性能表现。
- 增强模型可靠性:人类反馈的引入使得模型在决策过程中能够考虑到更多的因素,减少因环境噪声或数据偏差导致的错误决策。这有助于提高模型的稳定性和可靠性,使其在实际应用中更加可信。
- 促进模型道德和对齐:通过RLHF,我们可以确保模型的行为更加符合人类的道德和价值观。这对于一些涉及敏感信息或伦理问题的应用场景尤为重要,可以避免模型产生不当的输出或决策。
版权声明:本文转载自微信公众号-AI大模型前沿
若想了解更多有关油气行业大模型,赋能油气行业领域发展,可查看油气通GPT云平台,链相关接: https://cn.oilgasgpts.com/ ,也可使用手机扫描下方二位码进行查看。











 暂无评论
暂无评论
 关于作者
关于作者 热榜
热榜

 关注石油同学
关注石油同学  扫码进入移动端
扫码进入移动端 